From first clone to your own discovery
A problem-solving harness for quantum many-body lattice problems — ground-state and finite-temperature — plus the scientific-research skills around it. You drive it in plain language; it routes to the right method, runs the calculation, verifies the result, and hands you a script, plot, or document you can rerun. Everything below the fold is a real, captured run — the transcripts, plots, and reports are actual output, not mockups.
Early stage — contributors welcome; formal release planned for August 2026.
① Get started
Three steps from nothing to a guided training session. No prior experience with agents, Julia, or many-body methods assumed.
- Install an agent CLI — Claude Code, Codex CLI, or OpenCode. Don't have one? Follow the summer-school setup guide.
- Clone the harness and install its skills.
git clone https://github.com/QuantumBFS/quantum.harness cd quantum.harness make skills - Start the guided training. Paste into your agent:
It asks which track you want, then walks it one confirmed step at a time — every command is explained before it runs, and it never auto-solves for you./beginner-training
② Your training path
Five tracks, recommended in order — but each stands alone, so start anywhere. Every track ends with a checkpoint that proves the result is trustworthy instead of just claiming it.
③ What people use it for
Three journeys, each shown as a real captured run — open a card for the full annotated transcript and the actual plot.
Reproduce & challenge — the summer-school journey Harnessing Quantum 2026
The summer-school journey. You arrive on a method track, reproduce its reference result to calibrate yourself and the tooling, then invent a feasible challenge that goes beyond the paper and ship it. The harness guides each phase and teaches as it goes — it never auto-solves the challenge for you.
/onboardset up the stack/beginner-trainingguided training: pick a track/reproduce-paperreproduce the reference/challengego beyond it/challenge-reportclean PR + report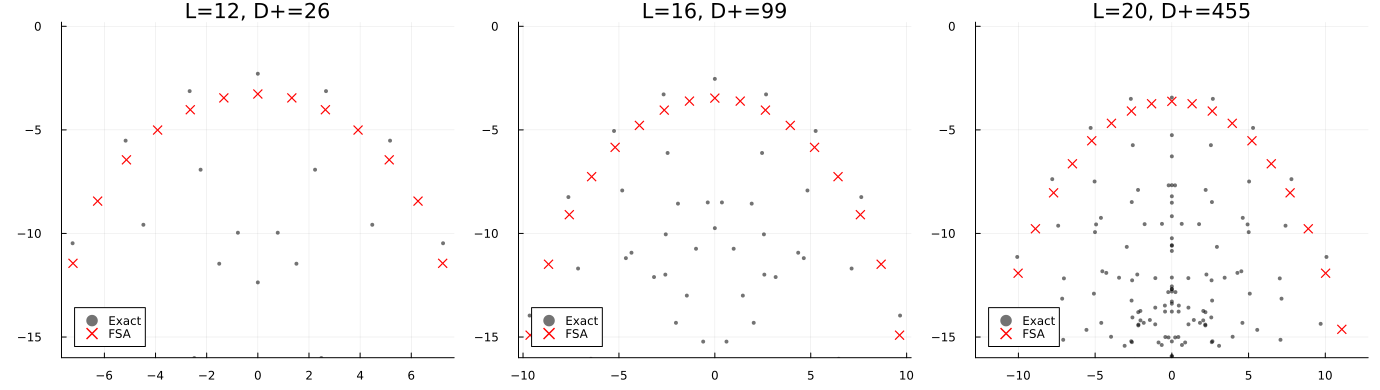
Bring your own problem — solve a model end to end Computational methods
The everyday path. State a concrete model in plain language; the harness infers the defaults, recommends a method, runs it, and verifies against a known limit. When the system gets too big for your laptop, the same run ships to the cluster unchanged. Heavy compute is a branch inside this workflow, not a separate one.
/solvestate the problem/method-mpspick the method/using-itensorspick the tool/using-slurmscale up (when heavy)/reportHTML writeup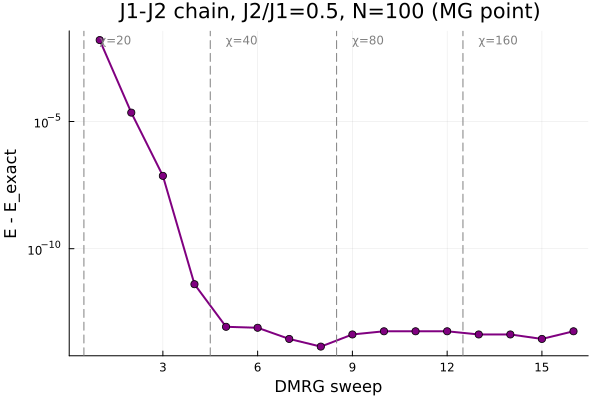
E − E_exact
vs sweep (log scale). At bond dimension χ=20 the error already drops below 1e-13 in four sweeps;
raising χ to 40/80/160 (dashed lines) holds it at the machine-precision floor. The flat floor
is the convergence proof — the calculation has nothing left to gain. Final
E₀/N = −0.375000, matching the Majumdar–Ghosh exact value.Survey & brainstorm — the sci-brain research skills sci-brain
The harness doesn't stop at numbers. The bundled sci-brain skills cover the research work around a calculation: mapping a field and writing it up, and brainstorming new directions with AI agents. Two flows below — a survey you can hand to a team, and an ideas report you can take to a help desk or advisor.
Survey writing
Map a research area from scratch: parallel search strategies build a literature knowledge base with BibTeX, the references are fetched and rendered to full text, then a structured state-of-the-art review is drafted section by section.
/surveyexplore + build KB/download-reffetch + render PDFs/survey-writerdraft the review
articles/2026-06-20-many-body-software-review.pdf — a real 5-page state-of-the-art
report built from a 53-reference knowledge base (24 papers rendered to
full text). Organized by technical approach (tensor networks, ED, QMC, VMC/NQS, DMFT), each with
its own state of the art and trade-offs.Brainstorming ideas with AI agents
A research collaborator that thinks with you. A warm mentor drives the conversation while a separate critic agent stress-tests every idea — the deal is "you think, I fetch": the agents surface facts, references, and cross-field connections; you do the deep reasoning. The converged direction becomes a structured ideas report.
/brainstorm-ideastwo-agent dialogue/idea-writerstructured proposalNeural quantum states near maximal frustration
- Research question
- Can a CNN-based neural quantum state reach DMRG-competitive energies for the 2D J₁–J₂ model at J₂/J₁ ≈ 0.5?
- Novelty
- Targets the exact regime where 2D DMRG area-law cost explodes.
- Why now / why you
- NetKet + JAX make the ansatz a few lines; you have the ED cross-check.
- Cross-field link
- Expressivity bounds borrowed from ML approximation theory.
- Min. viable exp.
- 6×6 lattice vs ED ground truth before scaling up.
- Success signal
- Energy within ED error bars at 6×6, then beats DMRG χ-limit at 10×10.
- Hope signal
- Not yet at ED accuracy, but error falls steadily with width.
- Pivot signal
- Variance plateaus far above ED — change ansatz or abandon.
/idea-writer
emits — research question, novelty, minimum viable experiment, and explicit success / hope / pivot
signals. (The survey above is a captured run; this brainstorming exchange is illustrative — the
dialogue is interactive by nature.)